On AI-assisted Web Search

This is the second part of a short series about Web searching / crawling. The first part is available here: Searching the Web with agents.
In the previous post I showed how to setup your own AI agent to help you search the Web. I used Pi, SearXNG, and llamafile for that, with the goal of allowing you full control over the whole system. But regardless of the stack you chose, AI-assisted Web search is, as AI-assisted coding, a new paradigm that we have not really fully explored yet. And like with coding, it is as powerful as brittle: you’ll be amazed at how proactive even local, open source LLMs can be, as well as how easily they can break. And while seeing what AI agents can do for you is quite exciting, you will also wonder about their impact on the Web and, consequently, on your lives.
This post is a natural continuation of the first one: you have set up your first search agent, and now want to understand what you can do with it. I’ll first show how you can choose and configure your llamafiles to work with realistic agentic workloads, then share some examples, and finally conclude with some personal thoughts about this approach to Web search.
Configuring llamafiles
Every language model can work on a fixed, finite amount of text at any given time. This is called context size and every local inference engine allows you to customize it. llamafiles currently ship with a default context size of 16384 tokens. As a llamafile is basically a zip file containing the inference server binary, the model weights, and a .args configuration file, you can verify what the context size is as follows (just pass your llamafile’s filename):
% unzip -p Qwen3.5-9B-Q8_0.llamafile .args
-m
/zip/Qwen3.5-9B-Q8_0.gguf
--mmproj
/zip/853698ce7aa6c7ba732478bad280240969ddf7b0fcbf93900046f63903a83383.gguf
--temp
0.7
--top-p
0.8
--top-k
20
--min-p
0.0
--presence-penalty
1.5
--repeat-penalty
1.0
--ctx-size
16384
...
Those 16K tokens might sound like a lot, until your agent has fetched a few moderately verbose Web pages and bumps into:
Error: Context size has been exceeded.
To prevent this from happening, you can run llamafile with a larger ctx-size value. Different models and model families come with their own context sizes: you can use the maximum value allowed (for Qwen3.5 models that’s 262144 tokens) by adding --ctx-size 0 to the command line, or choose an intermediate value that works better with your available memory. For example:
./Qwen3.5-9B-Q5_K_S.llamafile --ctx-size 40000
Why does llamafile limits itself to 16K tokens? Why shouldn’t one provide 0 by default? The thing is, the larger your context size the more RAM your model will need. Inference servers often come with conservative context sizes (e.g. Ollama has a default of 4K tokens). The smaller the default, the larger variety of models you can start without going OOM, but that only hides the real issue: if the context length is not large enough and your harness does not warn you, you won’t see anything break but results will still be crap, so you will likely blame the LLM (whose only fault is being able to read just a portion of the data it needs to answer your question).
In this circumstance, Pi behaves the best way possible: it immediately tells you there’s something wrong going on, so you can fix things from the start. With 16K tokens, llamafile has at least a chance to complete some agentic workflows, but will likely break while you run any non-trivial Web search. This is the reason why you should run it (as well as any other inference server) with a proper harness, or in server mode so you can check its logs and see if anything weird happens.
This teaches something about the trade-offs you will run into when playing with local AI. In this case RAM is the bottleneck: is it better to use a larger, more expressive model with a short context length, or a smaller model with a larger context? That very much depends on the amount of RAM you have available and on your task at hand.
To understand how much context length impacts RAM usage, I ran a small experiment starting a variety of llamafiles from the Qwen3.5 family with different context lengths (16K, 32K, 64K, 128K, and 256K). The results show that from a fixed amount of RAM required to load the model itself (the point where the plots start on the Y axis), memory grows basically linearly with the number of tokens, with a slope that varies depending on the model (smaller ones typically use fewer bytes per token). With a plot like this in your hands, you can draw conclusions like “I have 16GB of RAM, so I’d better use a 9B model with Q5 quantization and a 128K tokens context size for my agent rather a Q8 quant with 16K”, or prefer a Q5/4B combination if you need an even longer context length.
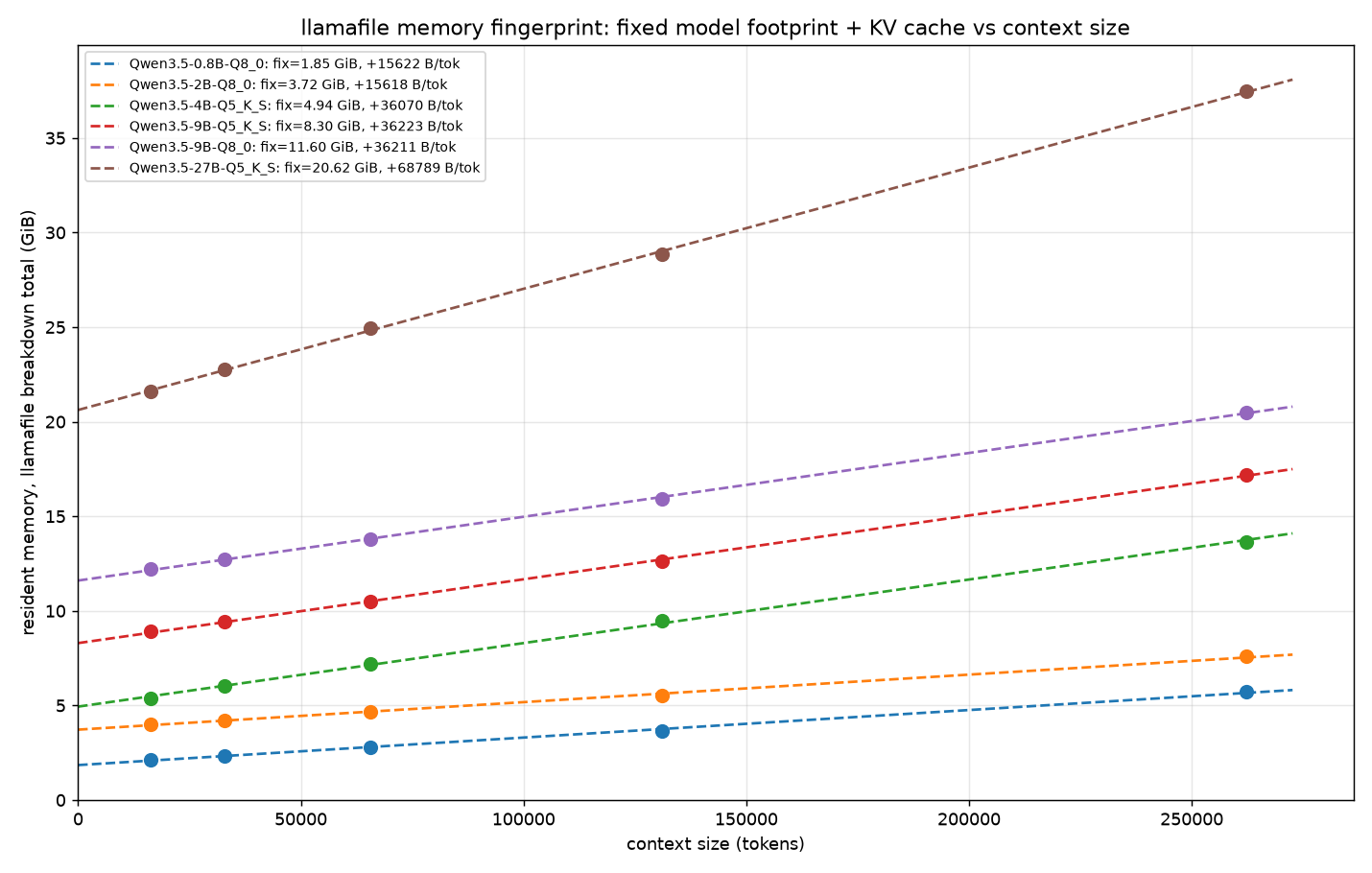
Note that the tool I wrote for the analysis directly reads RAM allocation data from llama.cpp’s logs, but I think all the information should already be available with the HuggingFace model and it’d be quite cool to have a tool that generates a plot like this out of a few HF model IDs. Probably something like that already exists, otherwise lmk if you decide to build one :-).
Experiments
I promised I would have spammed you with some traces from Pi, so let me show you some examples of searches I ran with the above setup. I wanted to test Qwen3.6:27B expressiveness, so I ran all of these experiments using this model. If you want to test the same tasks with the model you are running, just open these traces with Pi and /fork them at any step.
Did Mario Zechner do a talk where he stated that he just gets everything from an agent as an HTML slide show? I wanted to find an answer to this post on X so I just copy/pasted it into Pi. There are a few interesting things emerging from this trace:
the model used the
fetch_contenttool from the SearXNG extension, then fell back oncurlfor the following ones. I think the reason is that with curl it can pipe the output to other command line tools (e.g. grep, head), thus making the search more token-effective. This is a great point in favor of the “unix command line paradigm” and seeing this model behavior is very gratifying (now I am curious whether a smaller model would do this!)it looked like the model was running a lot of web searches without finding relevant information, but as it cited some YT videos I interrupted the search and asked if it could get transcripts from them. I thought it would have searched for how to do this, but it just used the shell tool to install yt-dlp and get transcripts on its own (which means it had pretty good yt-dlp knowledge in its training data)
finally, the model provided an answer based on the transcriptions, providing a quote and the related video / timestamp. I found it interesting that the model based its response on the fact that it did not find a quote from Mario but a very similar one from another person, and concluded this was likely a misattribution. Note that this is the kind of leap that commercial AI guardrails would be very conservative about, but given that this is a model we are running ourselves, and that we have citations and the whole trace to understand what the model did, I think it’s fair to say we got a more-than-decent answer (and btw, Mario confirmed he is quite sure he never said that 🙃).
While preparing this post I wanted to cite the proper quote with a reference, so I asked the question above to Claude. The answer was underwhelming, as it stuck to my verbatim sentence without any flexibility, then pushed back providing “closer to the opposite” quotes, and finally answered there was something related, but not verified.
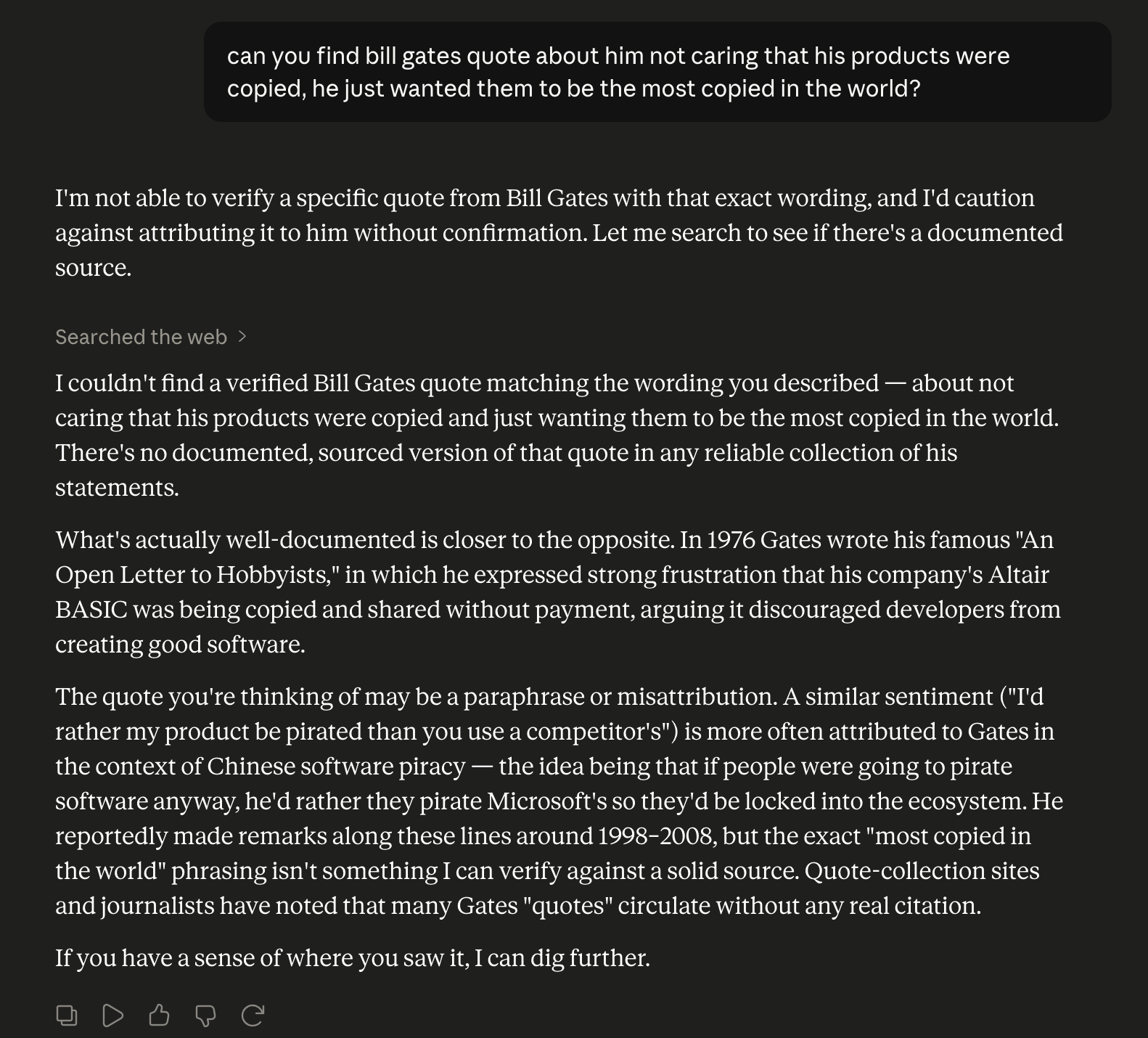
When I tried the same question with my local setup, I ended up with something way more interesting: the actual quote, despite the fact it was different from mine, and a reference to a few sources (just the names, not the URLs). When I asked for the actual links, I got five including this LA Times article which, to me, looked authoritative enough. When I asked for the original source cited by that article, the agent had some issues retrieving it because both the original URL and its archived version on the Wayback machine were dead, but it still provided me with more context, which to me was more than enough.
Intermission: the July 20, 1998 Fortune Issue, autographed by Gates and Buffett
This story has a second part: while writing this blog post, I wanted to see if I could push the agent further and I asked it to look for magazine archives, images collections, torrent engines, everything you think might be a good source of information.. While I still could not get the original Fortune article, I ended up with a PDF file supposedly copied from it and a YouTube video the Fortune article was transcribed from… And I can tell you where exactly in the video you can hear Bill Gates’ quote because I asked the agent to transcribe it and look for it! 🔥
In October 2000, +fravia gave a talk at Linux Day in Milan, where he introduced stalking as a way to gather information about potentially interesting websites:
“Unfortunately, in a more and more ‘commercial’ web, the number of bastards that ‘hide’ what they have found is increasing. Most of the juicy hidden sites are in the ‘outside linkers’ part of the web, with no link pointing back to them. How do we find them?”
The way he used the term “stalking” was kinda different from today, as he just wanted to find websites linking to his material, as they would have probably had other interesting content. I want to be mindful about today’s acceptation of the term though, and show an example of how easy it is to “connect the dots” when an automatic tool does that for you. Think about the fact that these tools can be used by many now, and reconsider what you feel comfortable sharing online.
I have been showing examples of small agents (backed by 9B models) finding my birthdate for a while now, so this time I pushed Qwen3:27B a bit further by asking to link different sources of information about myself. This information is not really hidden (and I definitely helped the agent with my own questions), but I found the result quite accurate as it gathered most of my public activity in the last ~30 years. The question for you now is: how much information have you already shared online, and how easily can it be linked together? Are you ok with that?
Why bother?
In my previous post I made a comparison between AI-assisted Web search and coding, and I am convinced there’s a strong parallel between them (as well as with any other technology that gets augmented by these new models). One thing they have in common is the slot-machine effect: it’s very easy to remember the jackpots and overseeing the failures. Trying to keep myself honest, I have used this search agent for a couple of months before starting to write anything and collected the examples you saw along the way. Here are my conclusions regarding the pros, the cons, and the open questions of this setup.
I still run “classic” searches most of the times, but since last September I have been always using SearXNG (running on my home Raspberry Pi) as my default search engine at home. When I need to delve deeper into a topic, find references for something I want to cite in a blog post, or gather material about existing projects (e.g. “cool AI projects running on a raspi 5”) I use the Pi+SearXNG+llamafile combination. I default to the largest and most expressive model I can run on my hardware (the 27B Qwen3.6), but I think that is often overkill. I’d be glad to see some proper experimental results in this sense though, instead of just relying on a feeling.
Searching with an agent takes more time, because (1) links are followed in realtime and (2) the LLM needs to parse contents and choose the next actions to take. I do not really care, as I usually leave the process running while I do something else. However, I want to be mindful about the fact that when websites are hit automatically they can easily be overloaded with requests (e.g. in the Bill Gates example, archive.org was hit almost 20 times to answer a single question). How does this scale when many people start using agents for search? Can we make sure that this approach is sustainable for those who share information on the Web?
About this, it’s interesting to see that LLMs default to some specific websites for given tasks. For instance, Qwen3.6:27B chose to look for the missing fortune article on archive.org. I saw this behavior before: when run without a search engine tool, GPT-OSS used to bomb Wikipedia with requests to answer most questions. And if you disable the pi-searxng extension you previously installed (you can do so with pi config) and suggest your agent to use curl to connect to the Web, Qwen3.* models will basically do the same. This raises a question whether (and for how long) we should trust pre-trained models to connect to reputable data sources, and more importantly who gets to choose them.
The search agent we built is definitely barebones, but intentionally so. I wanted to apply the same principle used by Pi, that is starting with few essentials and let the agent sort this out. The advantage is that the LLM is not overwhelmed by huge lists of tools it will never use, and it will figure out how to solve the same problems by piping together fewer, smaller, more versatile tools. This worked out nicely with the large model, but in my experience this is a bit more complicated with smaller models where you sometimes need to be more explicit.
It is worth noting that in these experiments the model always worked with either the HTML sources it downloaded with curl, or the Markdown returned by the fetch_content tool from pi-searxng (that uses Mozilla’s Readability to get the main contents of a page). This looked enough for the agent to answer my questions, but I am sure that a more powerful tool for content extraction and conversion might be able to access a wider variety of content and better serve it to the LLM.
Finally, being able to see everything that’s happening while you are running it is a great feeling. Going back to my grandpa’s “you must ride the bicycle, not the other way around!”, this is how you check where your bike is going and how, allowing you to grab the handle and steer or give a push on the pedals to keep your balance. Differently from a bike, the process you drive when Web searching generates new information, both along the way (the trace) and as a final artifact (the answer to your question). Being able to share both the process and the result as a public URL with Pi is great, as you can provide evidence of how you got to some conclusions, and teach how you got there at the same time. And as if this weren’t enough, traces are useful not just for people, but also for agents to learn how to do things better (see e.g. mozilla.ai’s cq project).
Where to next
It’s been two posts about AI Web search already and I still feel like I just scratched the surface of this topic. It’s understandable, as the field is wide and a lot of things are going on, but I want to leave you with some ideas about what to do next.
Most of the ideas boil down to answering the question “What is the perfect search agent for me?” Searching is an activity (going through different sources, gathering results, learning something new, then repeating the process with the extra information you got), not an action (entering a string, clicking Search, choosing one of the results). If you think about it this way, then it’s quite obvious you cannot really have a one-size-fits-all solution for it. Your search agent will be a mix of the agent components (remember the five primitives we talked about in the first post?) that work best for you.
Here are a few directions I consider worth exploring:
The pi-searxng extension I chose is intentionally simple, but SearXNG’s API is way more expressive. For instance, it allows one do search with date / language filters, or by category (e.g. images, videos, news, socials, etc.). And the engines are all configurable! I think making this information accessible to the LLM might be very useful for specific types of searches.
As I highlighted before, the scraping tool from pi-searxng is quite essential but if you follow online discussions (here’s a recent one for example) you’ll see there’s a plethora of different tools you can use to augment your search agent. Remember Pi’s paradigm and try to keep your agent lean, but feel free to experiment and learn what works best for your use case.
Play with different models, quantization levels, and context sizes to see which combination provides results you are happy about within the constraints of your actual hardware.
Speaking of hardware, I think it’s worth moving from the “local models” concept to the one of “owned models”. Who cares whether they are local if you still own and can control them? I love that the coding agents trend taught more people to self-host models in their home labs or in the cloud, accessing them via VPNs and remote access tools. I think we need to go one step further here, which is making it easier to share models and agents with other people, so that “your” model is not necessarily one in your apartment, but can be anywhere, shared with your research team, cooperative, or group of friends. I am quite proud to say that at Mozilla.ai we are doing something in this direction with Otari and its open source gateway, but as I always say it does not really matter which tool you use to do this, the important thing is that you get to own the technology you are running.
Play with your traces. LLMs have become pretty good at processing knowledge and more tools (e.g. memories, dreaming, LLM wikis) are being built that learn from past activities. Why can’t you? Just start asking Pi to read traces from your past searches and see if there’s anything that would improve future ones, and see what happens.
Share what you are doing. Pi developers gave us an awesome way of sharing our traces with other people. In the light of my previous suggestion, I believe both us and our agents could learn a lot from them, so why not actively share them?
Well, I think that’s it. I started the first of these two long posts citing Searchlores as a valuable (albeit perhaps a bit outdated) source of information about Web searching, and I guess I just closed the circle, by basically suggesting to have something similar for both people and agents 😬. Now it’s your turn: play with this open agentic search stack or try others, learn something new, and if you have anything you’d like to share I’d love to hear about it: you can find me on the Fediverse or, well… Use your search agent to find where 🙃