Own your AI agent: running open source agents on your terms (1/3)
Based on a lecture given with David de la Iglesia Castro in early May 2026.
What you are reading is the written version of a lecture David and I gave on building and running AI agents that you own completely. It starts from the assumption that even if a commercial AI service is not inherently bad, depending on one for everything definitely is. After providing a way to compare commercial and open source AI systems more fairly, we walk through the primitives that every modern agent is built from. With a series of concrete experiments with local models and tools, we explain how open source agents work and where they fail. The argument throughout is that you don’t have to depend on closed, rented systems for everything — and that you learn a lot more when you don’t.
Given the length of the lecture I decided to split this post in three parts. The document you are reading provides an introduction with motivations and background, part 2 walks you through the five primitives that most modern agents are built from, and part 3 presents a series of concrete experiments with local models and tools.
AI Disclaimer
I used AI to help me write this post as follows:
- I used whisperfile to transcribe the audio of our talk to a text file
- I used Claude Opus 4.7 with the following prompt to draft a blog post from the transcript and the slides:
I want to write a blog post about a presentation I recently did. The idea is to start from the transcription of the presentation and generate a markdown file which alternates screenshots of some of the presented slides and some explicative text.
I do not want to bring over everything I said in the talk as that's too verbose for a blog post, but I want to preserve the educational purpose. So: no flashy blog post tone, think about it as an "offline lecture".
I have both the transcription and the slides. The former has timestamps too so it should not be too hard to understand which part of the text refers to which slide.
Can you produce a markdown file we will iterate on?
- (… yeah, I am a bad prompter 😅). After I got this markdown file, I worked on it to get the final result you are reading here.
That’s it. I wanted the process to be 100% transparent to you, so you can make an informed choice whether you want to continue reading this or not.
I do want to repeat the same process with an OSS model, but I am quite sure it would need extra tools I have not played much with yet (I tried reading PDFs with multimodal models and llamafile, but I am not sure how well this would work with slides without much text). I’ll definitely do that, but I am also sharing both the inputs and the output so you can experiment with it too.
The parable of the impenitent reverser

The picture above (drawn by David Revoy) depicts Ada from Ada and Zangemann, a children’s book by Matthias Kirschner and Sandra Brandstätter (there’s also a beautiful animated video). The story features a man, Zangemann, who is a genius inventor. He builds wonderful tools for everyone — but each tool carries his own preferences, his own biases, his own decisions about what users should and shouldn’t be allowed to do. And on top of this, his tools cannot easily be modified. Ada is a little girl who pulls broken Zangemann devices out of the dumpster, takes them apart, and assembles and reprograms them into custom tools.
I strongly identify with Ada. Around her age I printed, with my dot matrix printer, my first business card that read “inventor”, and the way she approaches technology — by tinkering, by learning new things, by adapting tools to her own needs — is exactly the relationship I want to have with technology and AI.
Twenty years ago: PowerBrowsing
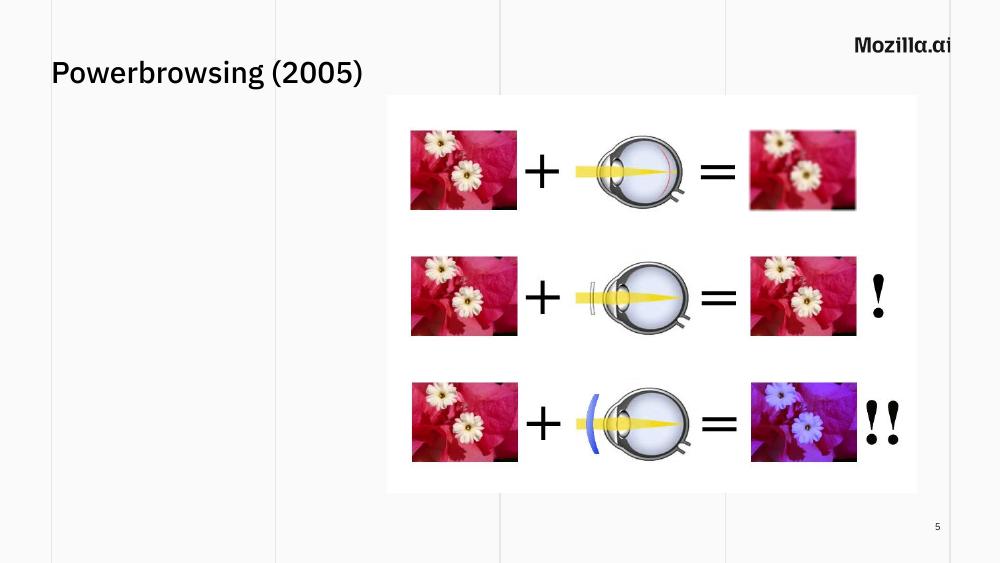
In 2005 I gave a series of talks about something I called PowerBrowsing. I started those talks with a very simple metaphor: we see reality through our eyes, but our eyes can be helped. If we have myopia, glasses correct what we see back to what’s really there. And using colored sunglasses we can also customize how we see things, bending reality to our preferences.
I wanted to apply the same idea to the web. In the early 2000s, websites were drowning in pop-ups and ads (we have, in some ways, returned to that). My “eye with bad eyesight” was… Internet Explorer 😬. The “corrected eye” was Firefox with an ad blocker. And the “sunglasses” were custom bots that would crawl a site, extract the actual content I cared about, and serve it to me cleanly. Just the information I wanted, even if it was not readily available in reality.

I built these tools in Perl, running on an old Compaq Armada that lived in a drawer in my house, connected to a slow DSL line and always on so I could query it from a Symbian phone. It was a nice experiment, with plenty of follow-up projects, and I learned a tremendous amount doing it.
One year ago: Vibe Reversing
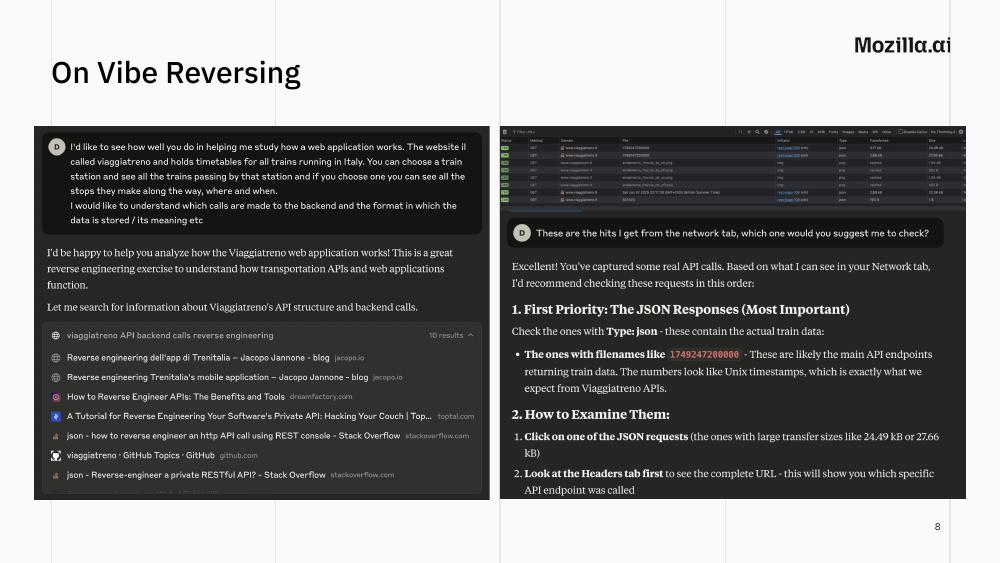
Last year I tried the same exercise again, but with Claude. The target was Viaggiatreno, the Italian railway website, which holds train timetables for every station in Italy. The purpose was getting the timetables without clicking through the website’s menus and ads, or installing yet another ad-hoc app. Not a very useful goal per se (I do not live in Italy anymore), but a useful task nonetheless as I had already successfully completed it twenty years earlier, so I could make a fair comparison.
The solution I implemented in 2005 was simple and compact, still it took me days to develop: I had to learn the site, practice Perl and regular expressions, write the crawler from scratch. This time I opened Claude, described the problem, and pasted a screenshot of the network tab. Claude found the JSON endpoints, suggested how to call them, and even built me a small UI. It worked basically out of the box.
So, is reverse engineering dead? Should we just ask Claude to do everything?

My experiment worked. But four things bothered me, leaving me uneasy:
- I had already done this before. I had enough prior knowledge to know whether Claude’s suggestions were right. Without that prior knowledge, would I have been able to verify the answer?
- The artifacts lived on Claude’s platform. If I had only asked “what time does this train leave?”, Claude would have answered — and I would have been dependent on Claude for every subsequent question. I had to remember to explicitly ask for the code, the script, something I could take home and run independently of a third-party service.
- Claude gave me excellent learning references. Which, if I had only wanted the quick answer, I would have skipped entirely.
- I wrote zero lines of code, and I learned nothing. Twenty years ago I came out the other side with knowledge of HTTP, of curl, of regular expressions — knowledge I have reused for two decades. This time I came out with basically nothing, except the precise answer to my questions.
On top of this, when I wrote a blog post about this and asked Claude to give the strongest possible criticism of my position, the reply was: “You’re a technical person telling non-technical people to make their lives harder to solve problems that mostly exist in your head.” 😅
That stung. So let me ask: are these problems just in my head?

Are you concerned about UX that changes from one week to the next? About inconsistent model performance? About sudden pricing changes — the thing that cost $20 last month and costs $50 this month? About sustainability, sharing personal data, the requirement to always be online, ads, lack of control?
If you answered yes to any of these, this post is for you. And just to add one example: while preparing this talk, the news came out that Elon Musk was offering compute to Anthropic. Aside from what opinion you have of Elon Musk, more intricate dependencies between AI companies today mean a higher chance of something going wrong tomorrow. I sleep better knowing at least some of what I do, I can do entirely under my own control.
A short philosophical detour
When I studied AI, my professor Marco Somalvico preached philosophy of AI to us almost every class. At the time I wasn’t sure I’d ever use any of it. Twenty years on, I use it almost daily. Two ideas in particular.
The machine is a place

Prof. Somalvico used to say: the machine is a place, where humans perform actions. The Mechanical Turk (the one before Amazon’s) wasn’t a metaphor, but literally a place with a person inside, moving the chess pieces. For us today the place is more abstract, but the principle holds: when you run someone’s code, it’s the machine that executes it, but it’s someone’s instructions that are run, either directly or indirectly.
Is this always true? Well, it definitely was when, during high school, I developed a solution to the “perfect 100” game (I am not sure that’s the official name, but I found an implementation here). It took some time on my old 386 PC, but it was definitely me who played that game (and had fun trying to find a smart solution, rather than bruteforcing it with a backtracking algorithm). Years later, we could all spot the lazy Microsoft developers (or Bill Gates himself) behind any of their crappy shareware protections. Today, it took a village of OSS developers to concretize my determination into finding the previous two links, but it’s them who I have to thank, even if agent traces show a somewhat autonomous system searching the Web in their stead (malatsol.jsonl, billgates.jsonl).
By this time you will have realized that I have added more and more level of indirectness to my examples. First, the choice was all mine. Then, they all came from a single company. Finally, they were baked into a system made by different components, each of which built by different people / teams. On top of this, the system itself seemed to have some degree of autonomy at runtime.
Does this change anything for us? I don’t believe so. I think the Mechanical Turk metaphor is useful to us, not much to determine whether the machine has any reasoning capabilities on its own, but rather to make us ask ourselves: what choices are baked into this machine? Who is playing inside it, and on whose terms?
The Chinese Room

John Searle, 1980. A person inside a room receives questions in Chinese through a slot. They don’t speak Chinese, but they have a very thick book mapping every possible input to a correct output. From the outside, the room appears to understand Chinese perfectly.
The argument is usually used to debate the “intelligence” component in Artificial Intelligence and whether a machine can still perform a task satisfactorily without necessarily understanding what it is doing. There are two thoughts here that I feel worth sharing. First, I do not really mind whether the room “really” understands, as long as it completes its tasks properly. Secondly, I want to be mindful about the opposite move: can I be fooled into thinking the room understands more than it does? Can I be betrayed by surface-level competence? What is the mental model I make of these systems and how realistic is it?
This is why probing the room, that is testing where it breaks and what it actually knows, is worth doing, even when you treat the model as a black box.
Apples with Apples
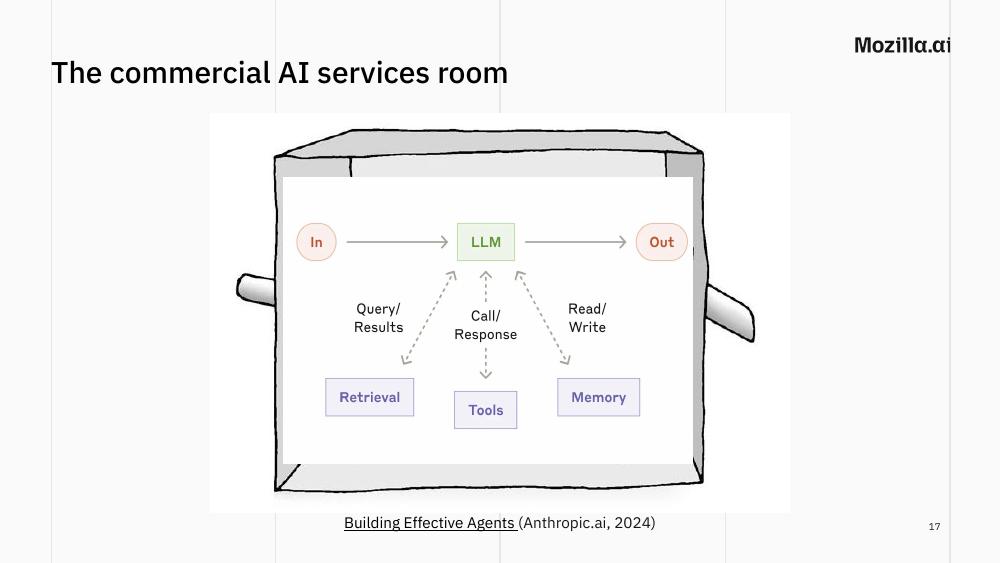
I often use the Chinese room argument to expose a comparison which is quite unfair. For a while, people have compared open-source LLMs to commercial AI services as follows: they ran a local LLM in a chat interface, asked it a few questions, and compared the result to ChatGPT or Claude. But, as Anthropic’s own diagram shows (in a post which now is almost two years old!), what AI services are built on are not just LLMs, but agents: that is, LLMs plus retrieval, plus tools, plus memory, plus a lot of engineering wrapped around all of it. So the fair comparison is not “commercial service vs. local LLM”. It’s “commercial service vs. local LLM with the same scaffolding commercial services have”.
Most open source AI projects don’t have the same resources commercial AI services have. But just in few months we have seen the gap between these two get smaller, thanks not only to more powerful open-weight LLMs, but also to the diffusion and adoption of open source agentic harnesses and frameworks. The rest of this lecture (as well as the following posts) will introduce you to what you need to (1) build that scaffolding yourself, either developing it from scratch or using available tools, and (2) evaluate whether you still need a commercial AI service for your task, or you can already move to using an open source alternative you fully own.