Building a Custom Feed on ATProto Part 2: Text-to-Feed with BYOTA and Embedding Similarity

This is a follow-up to Building a Custom Feed on ATProto. I wrote that post mostly as a way to note down how to run a custom feed - instructions were available but there were a few steps that were not obvious to me - and have a sandbox where I could easily experiment with different timeline algorithms. The application described in this post has been created starting from those notes, so I’d suggest you to check them out if you want to try and implement the same.
On June 5th I demoed BYOTA at Fediforum. While preparing for it, I realised it would have been hard to convey the message that BYOTA is not an application, especially if I just demoed it as a Web application. And while I have always liked the “100% local” message, I have also always been more interested in “100% yours”, i.e. under your control whether running locally or not. I also wanted to see (and show) ways to adopt the BYOTA approach at a different level, closer to the protocol layer, so that running it in one place would affect your experience anywhere, regardless of the client or device you are using to access the Fediverse.
For this reason, I chose to catch the lowest-hanging fruit and try to build something on top of my previous experiments with ATProto. I am not super proud of this because, as I had written in that post, my intention was to prioritize ActivityPub instead… The reason why I chose ATProto was that I had invested basically all my free time improving BYOTA’s multi-account support, and ended up with less than one day to develop something protocol-level. Looking at the bright side, you now have both the ATProto timeline and cross-instance search and recommendations across different Mastodon accounts :smile:.
So, how low-hanging was this fruit? Well, just look and see…
Writing the code
The following are the only changes I made to the original bluesky-feed-generator code. Apart from making logging a bit less verbose, what I do is:
import
LLamafileEmbeddingServicefrom BYOTA (whose sources I just copied into the/serverdirectory of the cloned feed generator repo) and numpy (for dot product calculation)instantiate the embedding service by providing the URL of the local embedding server (more on how I started it below)
calculate a reference embedding to compare new posts to. In this simple case, we embed a “filter string” which will be loosely compared to the new posts' embeddings. For the demo specifically, as pride month had just started, I used
"pride month, lgbtqia+, ally, love"change filtering so that instead of checking for the presence of the “python” string in new posts we perform a more loose comparison based on semantic similarity: new posts are embedded, then the similarity (in terms of dot product) between these embeddings and the reference one is calculated, and only those posts whose similarity is greater than 0.5 are added to the feed.
As you can see below, it literally takes more text to explain than to implement this.
diff --git a/server/data_filter.py b/server/data_filter.py
index 8149692..9044009 100644
--- a/server/data_filter.py
+++ b/server/data_filter.py
@@ -1,13 +1,17 @@
import datetime
+import numpy as np
from collections import defaultdict
from atproto import models
+from byota.embeddings import LLamafileEmbeddingService
from server import config
from server.logger import logger
from server.database import db, Post
+e = LLamafileEmbeddingService(url="http://localhost:8080/embedding")
+reference_embedding = e.calculate_embeddings(["pride month, lgbtqia+, ally, love"])[0]
def is_archive_post(record: 'models.AppBskyFeedPost.Record') -> bool:
# Sometimes users will import old posts from Twitter/X which con flood a feed with
@@ -58,20 +62,23 @@ def operations_callback(ops: defaultdict) -> None:
inlined_text = record.text.replace('\n', ' ')
# print all texts just as demo that data stream works
- logger.debug(
- f'NEW POST '
- f'[CREATED_AT={record.created_at}]'
- f'[AUTHOR={author}]'
- f'[WITH_IMAGE={post_with_images}]'
- f'[WITH_VIDEO={post_with_video}]'
- f': {inlined_text}'
- )
+ # (removed for a lighter log)
+ #logger.debug(
+ # f'NEW POST '
+ # f'[CREATED_AT={record.created_at}]'
+ # f'[AUTHOR={author}]'
+ # f'[WITH_IMAGE={post_with_images}]'
+ # f'[WITH_VIDEO={post_with_video}]'
+ # f': {inlined_text}'
+ #)
if should_ignore_post(created_post):
continue
- # only python-related posts
- if 'python' in record.text.lower():
+ # only posts semantically related to the filter string
+ emb = e.calculate_embeddings([record.text.lower()])[0]
+ if bool(np.dot(reference_embedding, emb.T) > 0.5):
reply_root = reply_parent = None
if record.reply:
reply_root = record.reply.root.uri
@@ -89,7 +96,8 @@ def operations_callback(ops: defaultdict) -> None:
if posts_to_delete:
post_uris_to_delete = [post['uri'] for post in posts_to_delete]
Post.delete().where(Post.uri.in_(post_uris_to_delete))
- logger.debug(f'Deleted from feed: {len(post_uris_to_delete)}')
+ # (removed for a lighter log)
+ #logger.debug(f'Deleted from feed: {len(post_uris_to_delete)}')
if posts_to_create:
with db.atomic():
Running the Feed
The first requirement to run the new code is having an embedding server running at the right port. To do this, I simply ran the docker container from the BYOTA demo, without mapping the port for the marimo UI:
docker run -it -p 8080:8080 mzdotai/byota:latest demo.py
Then, I simply followed the steps detailed in the first post of this series:
I mapped a domain name to the IP address of the server I wanted to run the feed on and set up TLS certificates for it
I made sure I could run the feed on port 443 by executing the following as root:
PYTHONPATH=/home/mala/bluesky-feed-generator/server/ flask run -h 0.0.0.0 -p 443 --cert /etc/letsencrypt/live/my.domain.name/fullchain.pem --key /etc/letsencrypt/live/my.domain.name/privkey.pem
The result (also documented here) was a “pride month” feed running live on Bluesky, driven just by a simple filter string and some text embeddings (no personal data was used to generate it):
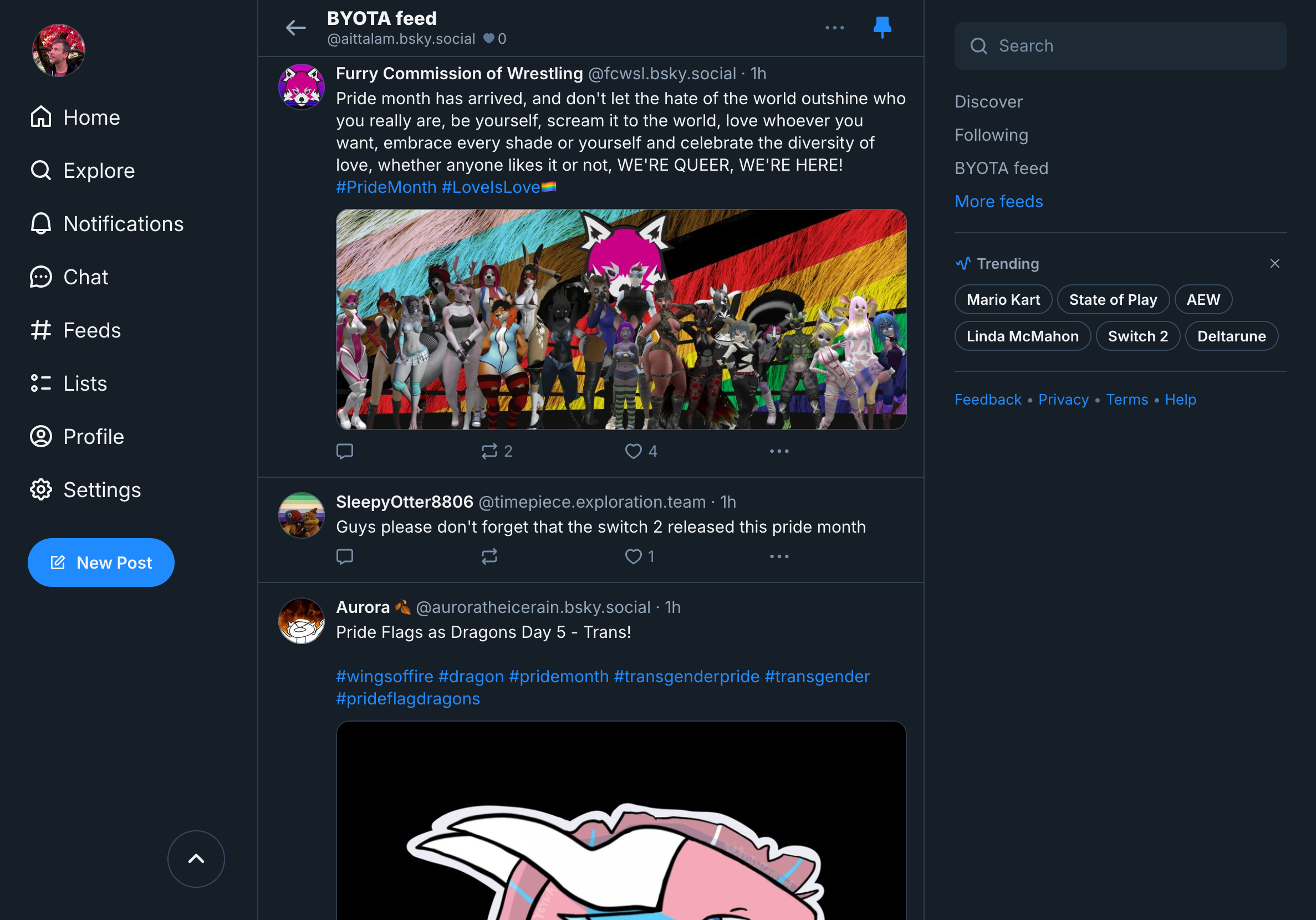
Conclusions
As you can see, the fruit was quite low-hanging indeed. I think this was due to a mix of concurrent technical choices:
on the one hand, the BYOTA code was modular enough to allow me to simply import it into somebody else’s code and run it (I still feel like it is prototype quality, but at least this thing worked out-of-the-box)
on the other hand, the design of ATProto allowed me to get to the result I wanted by focusing my efforts on a tiny portion of the code. I am quite sure problems will arise if I decide to run this timeline for more than a demo, still it was quite surprising to me that I could come up with a PoC so quickly.
Another thing I’d like to note is that all of this ran on a Raspberry Pi 5. This was great news to me, as in the spirit of owning my technologies I want to be able to host my algorithms, but possibly without spending a fortune.
… What are the next steps from here?
Well, I think this demo just scratched the surface of what could be done. The thing I liked the most was the possibility of dropping plain string search in favor of embedding-based semantic search, and I think delving more in that direction would be quite interesting. I would also like to use the same approach I used in BYOTA (dot product between new posts and a set of reference posts that provide “the style” of what one’s interested in) and implement a ranking mechanism: scores are calculated and stored for posts when they come in, possibly filtering out very low-ranking posts, then when the timeline is requested posts are returned ranked by score.
But more importantly, I want to focus my efforts on ActivityPub now and think about different levels at which one could apply this approach. I say different levels because I want people to have a choice regarding where (and especially whether!) they want to use algorithms in their feeds, following the same principles BYOTA has been built with.