Build Your Own Timeline Algorithm
(this post was written as a follow-up to my FOSDEM talk, but of course, well, life happened ¯\_(ツ)_/¯ and TWO MONTHS passed since then… In the meantime, BYOTA has become a Mozilla.ai blueprint and you can now both play with its code and with a demo on HuggingFace spaces. While the Mozilla.ai blog post linked above describes the blueprint with higher detail, here you’ll find a more personal take about my project)
Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes. Objectives might differ, from delving deeper into a topic to connecting with like-minded communities, solving a problem or just passing time until the bus arrives. How these objectives are reached might differ too, e.g. while respecting instances’ bandwidth, one’s own as well as others’ privacy, algorithm trustworthiness and software licenses.
This blog post introduces an approach to personal, local timeline algorithms that people can either run out-of-the-box or customize. The approach relies on a stack which makes use of Mastodon.py to get recent timeline data (but this could be customized for any social network which still offers an API to its users), llamafile to calculate text embeddings locally, and marimo to provide a UI that runs in one’s own browser. Using this stack, you will learn how to perform search, grouping, and recommendation of posts from the Fediverse without any of them leaving your computer.
Let that sink in
Despite being published more than one year ago, the Nature paper “Drivers of social influence in the Twitter migration to Mastodon” by La Cava et al. seems so current when it says “After years of steady growth, popular social media are experiencing shifts in user engagement.” The paper was referring to the abrupt #TwitterMigration following Elon Musk’s acquisition of Twitter in October 2022, but similar events followed since then, the most recent one following Mark Zuckerberg’s declarations last January.
I joined the Fediverse around May 2022 and there I found some great communities of practice that resonated a lot with me. Each community had different size, characteristics, language, message frequency. Everything I read was because I chose so: I could see posts from people I followed, search by keywords or tags, or read local and federated timelines when I wanted to look for something out of my personal bubble. The only algorithm available was the so-called “reverse chronological”, with all its pros (no ads, only posts from people you follow) and cons (unless you read everything, you’ll likely miss some statuses published while you were asleep). That’s where I started to think about the idea of a “personal algorithm”: something that I could customize and experiment with, and then share with other people so that they could do the same if they wanted, or just use it as a black box as long as they trusted the source.
An apology of (some) algorithms
This is what the Build Your Own Timeline Algorithm (BYOTA) idea is about: it is not a new algorithm, an end-user application, or a service, but rather a call for action, and a playground where people can easily tinker with, create, and share their own algorithms. To build this playground, I decided to delve deeper not just into platform algorithms (which I had already experienced while working at Twitter), but also into existing projects developed on the Fediverse. If you want to have a clearer idea of how platform algorithms and in particular recommenders work, this blog post (part of an excellent series!) by Luke Thorburn is a great starting point. For what concerns algorithms running on the Fediverse, the following provide some good food for thought:
- Searchtodon by Jan Lehnardt
- Mastodon Digest by Matt Hodges
- TootFinder by Matthias Bürcher
- FediView by Adam Hill
- Fedi-Feed by Philip Kreißel
Every algorithm I saw, no matter whether running on a closed platform or the Fediverse, was affected by one or more of the following problems: bias; lack of privacy, transparency, and user control; dependency on ML algorithms which are complex, computationally heavy and require to run in a centralized way. Reverse chronological itself -which many welcome as absence of an algorithm- is indeed an algorithm and it is biased too, as it generally favors statuses by people who write more and in the same timezone as me. Another, more important, thing I realised is that, in practice, all the above are actual problems only when the objective is to retain users on one’s platform. We can break this assumption though, by deciding that we do not need to compete with commercial algorithms: this is not a mandate for distributed social networks, and serving people’s purposes is more than enough.

When the objective changes, one can immediately realize there is a solution to each of the problems previously described. A solution that relies on open, small, interpretable models that can be run locally for ad-hoc tasks without requiring too much ML knowledge. One that only requires post contents to provide semantically relevant search results and recommendations, by relying on sentence embeddings.
BYOTA’s building blocks
BYOTA is built on this assumption: do something useful while preserving user privacy and control, using open models and local-first technologies. While the concept sounds quite straightforward, developing something which is easy to use and customize, and at the same time computationally light and useful, is not as simple. Luckily, there are some great tools we can rely on for this: Mastodon.py, llamafile, and marimo.
Mastodon.py (MIT License) is a python client library for Mastodon. You’ll use it to download new posts from your instance’s timelines. As what you need are just status contents, you can swap this library with anything else that provides you with similar short texts: a generic ActivityPub client, a specific one for a different social network’s API, a browser extension, an RSS feed reader, and so on. You can also use a mix of these if you want to play with cross-platform search and recommendations.
Llamafile (Apache 2.0 License) is a Mozilla tool that packages a language model in a single executable file that will run on most platforms. It is 100% local and has been optimized to run on slower hardware, from Raspberry Pis to my 9-years-old laptop. It is based on llama.cpp which supports a plethora of models, not just LLMs. In particular, I chose all-minilm because it is a sentence transformer model, specialized in calculating embeddings from text. It is tiny (50MB) and has open code, research papers, and datasets. Note that llamafile is a swappable component as well: if you already have a favorite embedding server, you can use it instead of llamafile as long as it is compatible with its API (and even if it is not, writing a new adapter is quite simple).
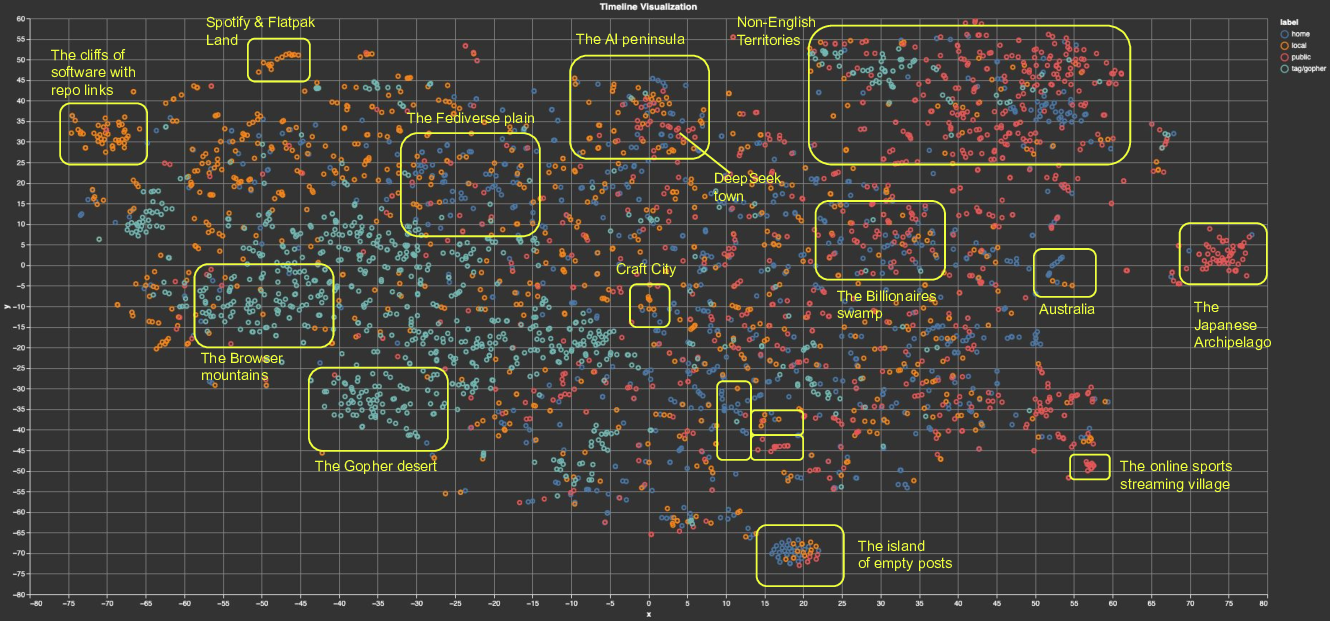
Now, let’s talk embeddings: if you don’t know what they are, you can just think about them as numerical descriptors of your Mastodon statuses, which are closer -as in two cities’ coordinates being close on a map- the more semantically similar their respective statuses are (see the “Mastodon map” figure below). If you want to learn more about embeddings, check out Vicki Boykis’ excellent paper.
Marimo (Apache 2.0 License) is a reactive notebook for Python, that is also sharable as an application. It mixes code, markdown and UI widgets in the same interface so you can (1) develop as you would do with other notebook environments, (2) share it as an application by hiding the code and only displaying the UI components, (3) allow people to build their own UI on a grid-based canvas, fully customizing their experience. Above all, marimo relies on WASM to run everything inside one’s browser. This is what that means in practice: you can download a marimo notebook from its repo, install its python dependencies, and run it locally as any python notebook; but you can also deploy it as HTML+Javascript files, host it somewhere super cheap (because the server will not run any of your code), and people will be able to run it in their browser with no need to install anything else.
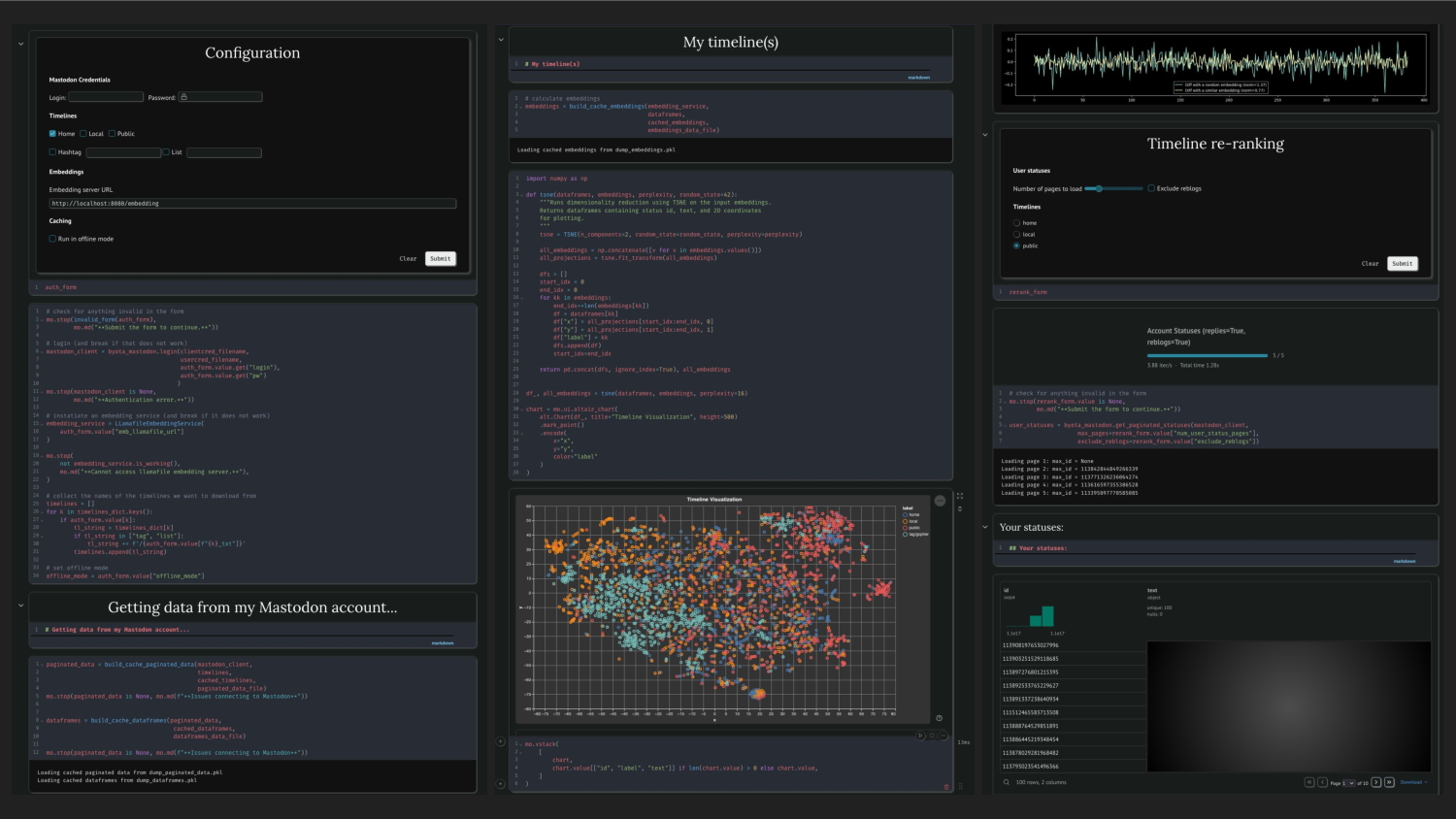
What you can do with BYOTA
When you run the BYOTA notebook, you first log into your mastodon account and download statuses from a few chosen timelines (you can find more information about the initial setup in the README.md file). After that, the first component you can play with is the one visualizing post embeddings.
In the figure right at the top of this blog post you can see a 2D plot of embeddings collected from four different timelines: home (blue, only people I follow), local (orange, all posts from my instance, which is fosstodon.org), public (red, federated posts from people followed by users of my instance), and the timeline that I got searching for the #gopher hashtag (light blue). Using the visualization tool, I have manually selected, analyzed, and annotated a few areas of this map. Semantically similar statuses will always be close to each other regardless of which timeline they appeared in, so from this view you can follow similar content across different timelines. This is simple to grasp and easy to interpret, as it is based on the actual posts’ content.
When semantic similarity is encoded by embeddings, one can easily develop semantic search by distance: a search field in the notebook allows you to provide a status ID (which you can get by selecting a post in the map) and look for the statuses (default is top 5) which are most similar to it. You can also just make up a sentence that describes what you are interested in and get results from different timelines.
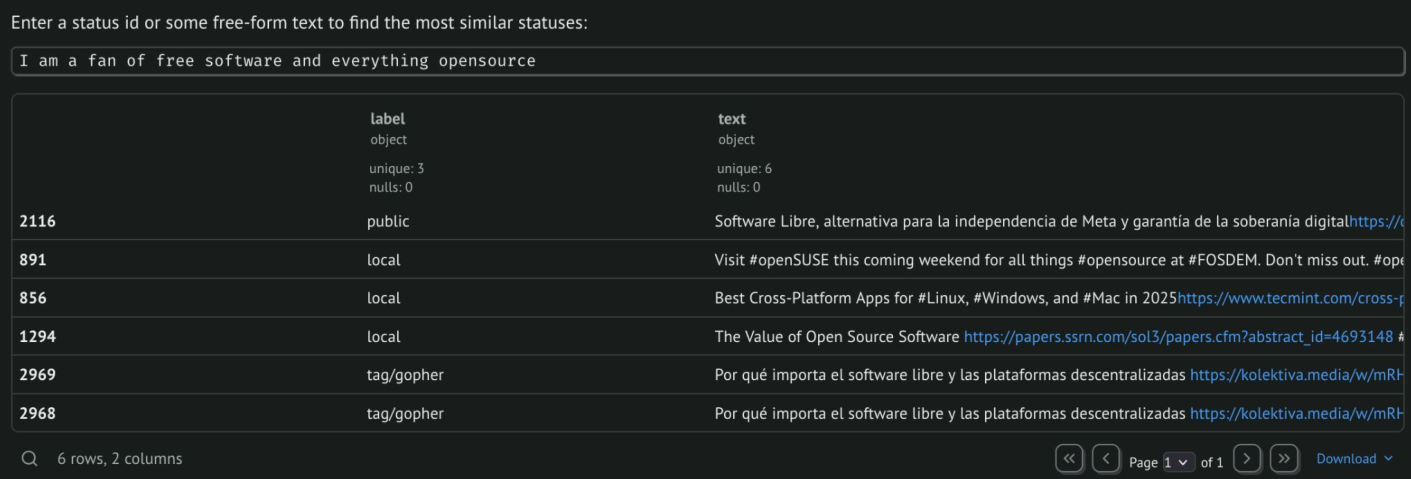
Another available feature is post re-ranking. To perform this, each post in a given timeline is assigned a score that depends on its similarity to another whole set of posts. For instance, you can re-rank the latest 800 statuses from your local timeline by:
- comparing each of them with e.g. each of the last 50 posts you wrote, liked, or boosted (to do this, you can use some measure of vector similarity, e.g. dot product or cosine distance);
- assigning a score which results from the accumulation of those 50 similarity values (e.g. a simple sum of them);
- sorting the 800 posts by their score in descending order.
The interesting part here is that the choice of which timeline to sort is yours: you can surface posts closest to your interests just from people you follow (home timeline), from users of your same instance (local timeline), or from other instances (federated timeline). You can also re-rank the results of a keyword or hashtag search.
Another thing you are in control of is what you use to provide the “style” for your re-ranking. Your last 50 posts is just an example, but you can pick different sets depending on what you are looking for at any given time. Basically you have a content-based re-ranking of any timeline: you basically apply the “style” of a set of statuses to another list, by putting on top those statuses which are overall closer to the ones you provided. As an example, the figures below show the same list of messages I wrote on Mastodon, re-ranked according to the “style” provided by the #gopher and #bookstodon hashtag search results.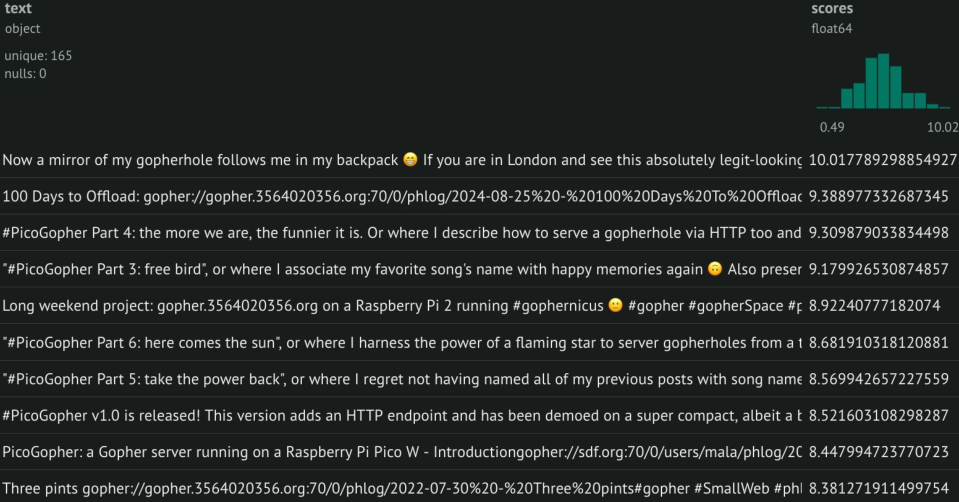 My own posts, re-ranked according to their similarity to posts in #gopher.
My own posts, re-ranked according to their similarity to posts in #gopher.
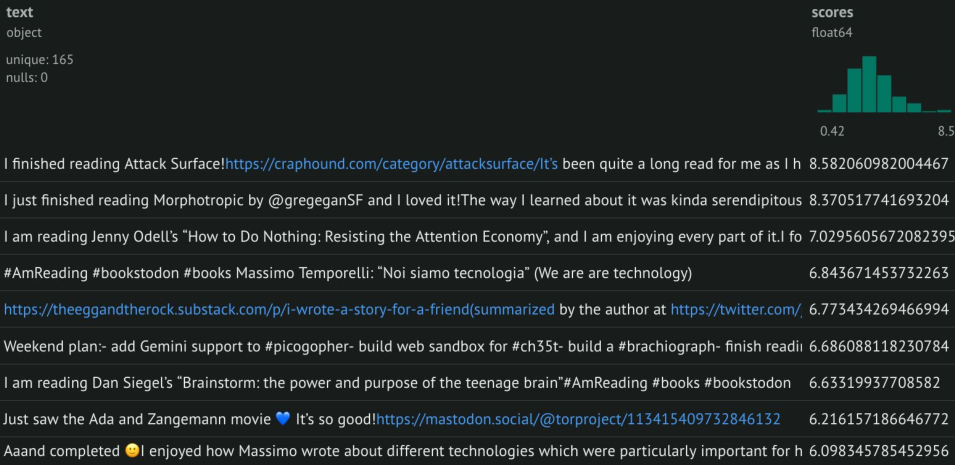 My own posts, re-ranked according to their similarity to posts in #bookstodon.
My own posts, re-ranked according to their similarity to posts in #bookstodon.
Does this really work?
One of the main issues when building open tools is ending up with something that people would not eventually use. For algorithmic timelines, in particular, the main concern I saw that prevented the adoption of new tools was privacy: people did not want their personal information to leave their own computers, nor anything they had already made public to be used by some centralized algorithms. The mandate then becomes to run everything locally, with the two very natural questions: “Is this really local?” and “Does this really run on my computer?”
“Is this really local?”
The answer is: check yourself. I ran the embedding server on a plane (and no, I am not paying for that poor wifi!). And for the notebook, you can verify with your browser’s developer tools that the only remote connections you’ll have to do are those related to the marimo and WASM dependencies at bootstrap time, and those required to download posts from your mastodon instance using the timelines API. You are always in control of which and how many messages you download before running the algorithm. From then on (embeddings, plots, search, re-ranking) everything runs on your device. The most interesting part is that it does not have to be local, but you are in control of it: for instance, if you cannot run a local embedding server you can rely on a remote one, choosing which software and model it will run and where. You can run the python code on a server in your local network or in the cloud, if you trust your provider, or you can simply host the HTML/WASM version of your notebook and let clients download timeline data and run the algorithm.
“Does this really run on my computer?”
About two years ago I tried embedding all the messages I could download from my Mastodon timeline using the tweet-topic-21-multi model, and I hit a wall when I realised it took three full minutes on my 2016 MacBook Pro. So, when I had a chance to run optimized, llama.cpp embedding servers, I wanted to repeat the same kind of experiment: I embedded 800 statuses using four different models, from the 22M-parameters all-MiniLM to the 7B e5-mistral. I tested them with two different local servers, llamafile and ollama, and two different laptops, my 2016 MacBook Pro with Intel CPU and my 2024 one with M3 Max. The results are shown in the table below. The summary is: it can work on older hardware, and on recent one you will barely notice the calculation overhead.
All-miniLM took 11 sec on M3, 52 sec on my 9yo laptop. And the embeddings are already good! Larger models might provide extra perks (which I have not investigated yet) but at the price of higher compute. Interestingly, despite the fact that both ollama and llamafile are based on llama.cpp, ollama seems to be faster on newer hardware / smaller models, while llamafile becomes a better choice for larger models on older hardware. Finally, I used default parameters for both servers so there is definitely space for improvement.

Conclusions
Given how custom the Fediverse experience is, I do not really think everyone needs a timeline algorithm. What I believe, though, is that if someone ever needs one, then BYOTA can be a more than decent starting point. This is definitely still a work in progress with many possible directions to grow, among them the ones I find most interesting are:
- the “protocols, not platforms” approach, i.e. can we abstract from the specific platform and work at protocol level, so that ranked timelines are available to different clients?
- increasing customization, i.e. testing and evaluating different embedding servers, models, and so on
- adding new algorithms (e.g. clustering, classification)
- going multimodal (what if you could e.g. automatically blur all posts showing… broccoli?)
… But above all, I’d like to hear from you! If you are interested in this topic, you can also check out my talk at FOSDEM or its Mastodon thread companion and play with the latest code. If you have any comments or questions, feel free to reach out at my_first_name at mozilla.ai or -obviously- on the Fediverse ;-)